포스팅을 하다보니 flexible jeykll에는 목록 기능이 없는게 좀 아쉽네요.
다른 테마를 찾는 중이에요. 아직 마음에 드는 테마를 찾지 못한 상태😂
이번 포스팅은 레이스 컨디션과 크리티컬 섹션에 관한 거에요! 정리 시작합니다.
KOCW 공개 강의: 반효경, 운영체제와 정보기술의 원리
Race condition
컴퓨터에서 연산을 할 때, 메모리에서 데이터를 읽어와서 CPU가 연산을 하고 그 결과를 다시 메모리가 갖다 씁니다.
하나의 공유 데이터를 여럿이 동시에 접근할 때 생기는 문제를 Race Condition(경쟁 상태)라고 합니다.
메모리를 공유하는 CPU가 여러 개인 경우, Race Condition의 가능성이 있습니다.
운영체제에서 Race Condition은 언제 발생하는 가
프로세스가 시스템 콜을 하여 커널 모드로 수행 중인데 context switch가 일어나는 경우
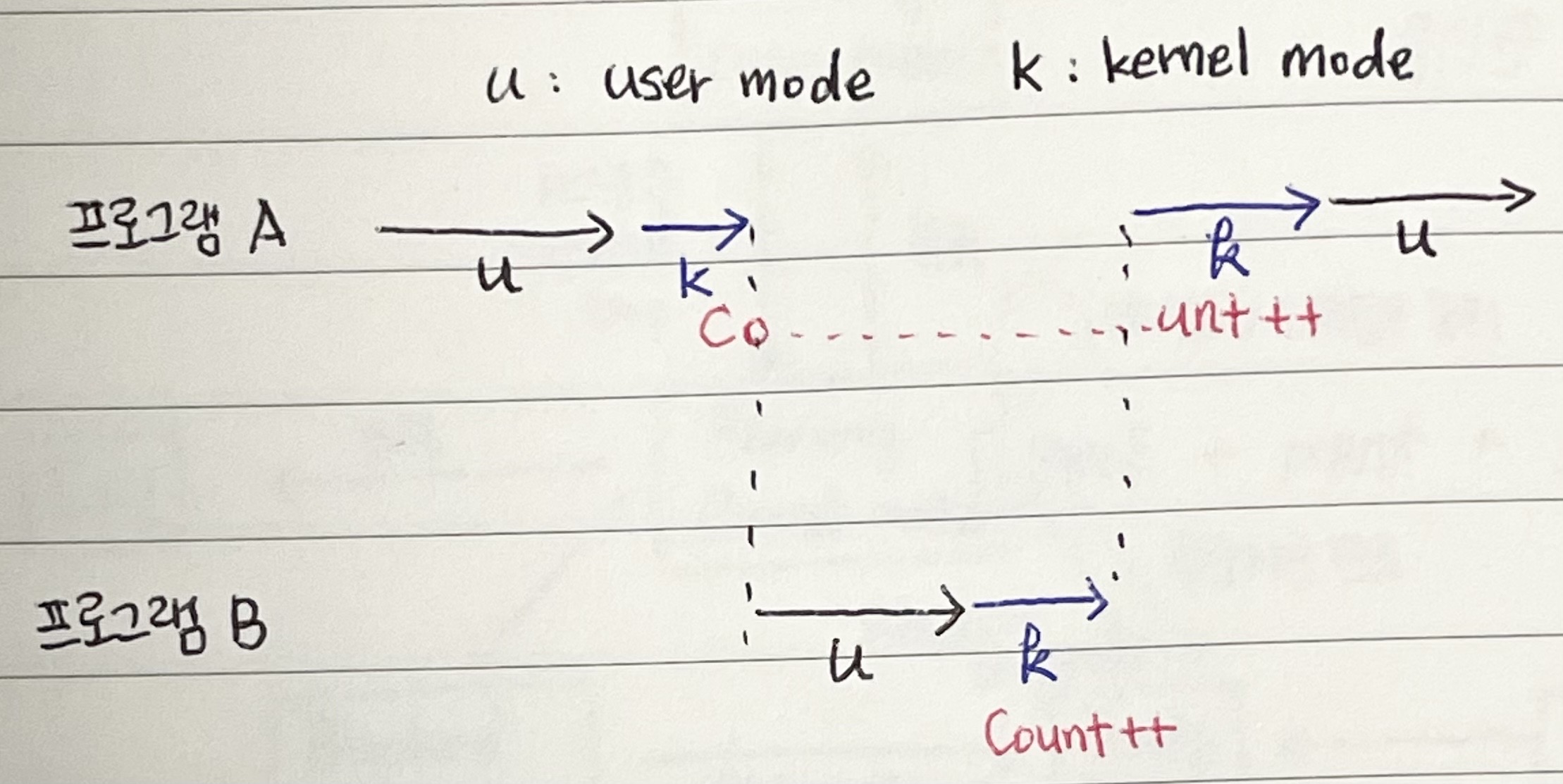
두 프로세스의 address space 간에는 data sharing이 없습니다.
시스템 콜을 하는 동안에는 커널 address space의 data에 접근하게 됨(share)
이 작업 중간에 CPU를 preempt해가면 race condition 발생
[해결책]
커널 모드에서 수행 중일 때는 CPU를 preempt하지 않는다. 커널 모드에서 사용자 모드로 돌아갈 때 preempt!
커널 수행 중 인터럽트 발생 시
커널 모드 running 중 인터럽트가 발생하여 인터럽트 처리 루틴이 수행됐을 때
→ 양쪽 다 커널 코드이므로 커널의 주소공간을 공유하므로 Race condition이 발생할 수 있어요.
[해결책]
커널의 코드(count 변수)를 건드리기 전에 인터럽트를 disable 시키고 작업이 끝난 후 인터럽트를 enable 시킵니다.
Multiprocessor에서 공유 메모리 내의 커널 데이터
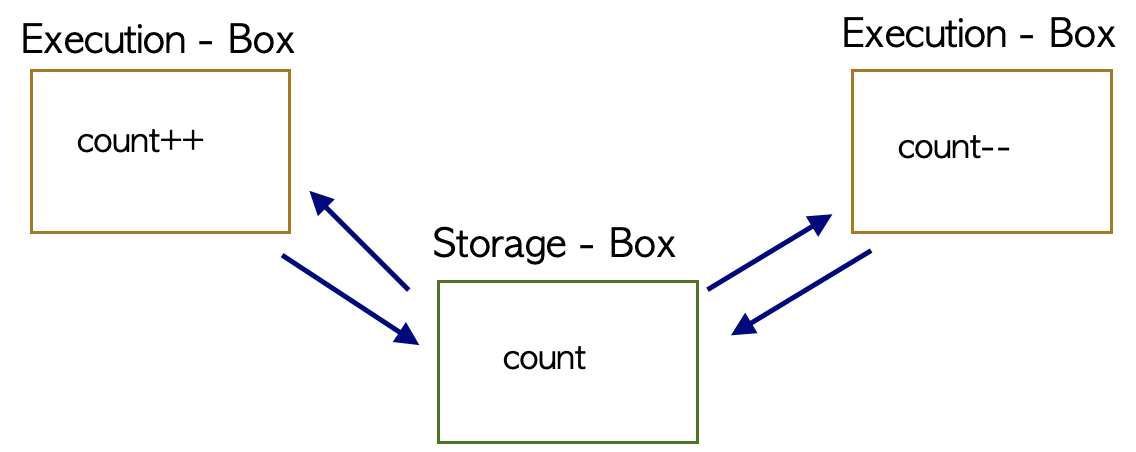
S-box = Memory, Address Space
E-box = CPU, Process
어떤 CPU가 마지막으로 count를 저장했는가?? → Race Condition!!
멀티 프로세서인 경우 인터럽트 enable/disable로 해결이 되지 않습니다.
[해결책]
- 한번에 하나의 CPU만 커널에 들어갈 수 있게 한다.
- 커널 내부에 있는 공유 데이터에 접근 할 때마다 그 데이터에 대한 lock/unlock을 한다.
프로세스 Synchronization 문제
공유 데이터의 동시 접근(concurrent access)은 데이터의 불일치 문제를 발생 시킬 수 있다.
일관성 유지를 위해서는 협력 프로세스(cooperating process) 간의 실행 순서를 정해주는 메커니즘이 필요.
Race condition을 막기 위해서는 concurrent process는 동기화 되어야 한다.
[Race Condition 예시]
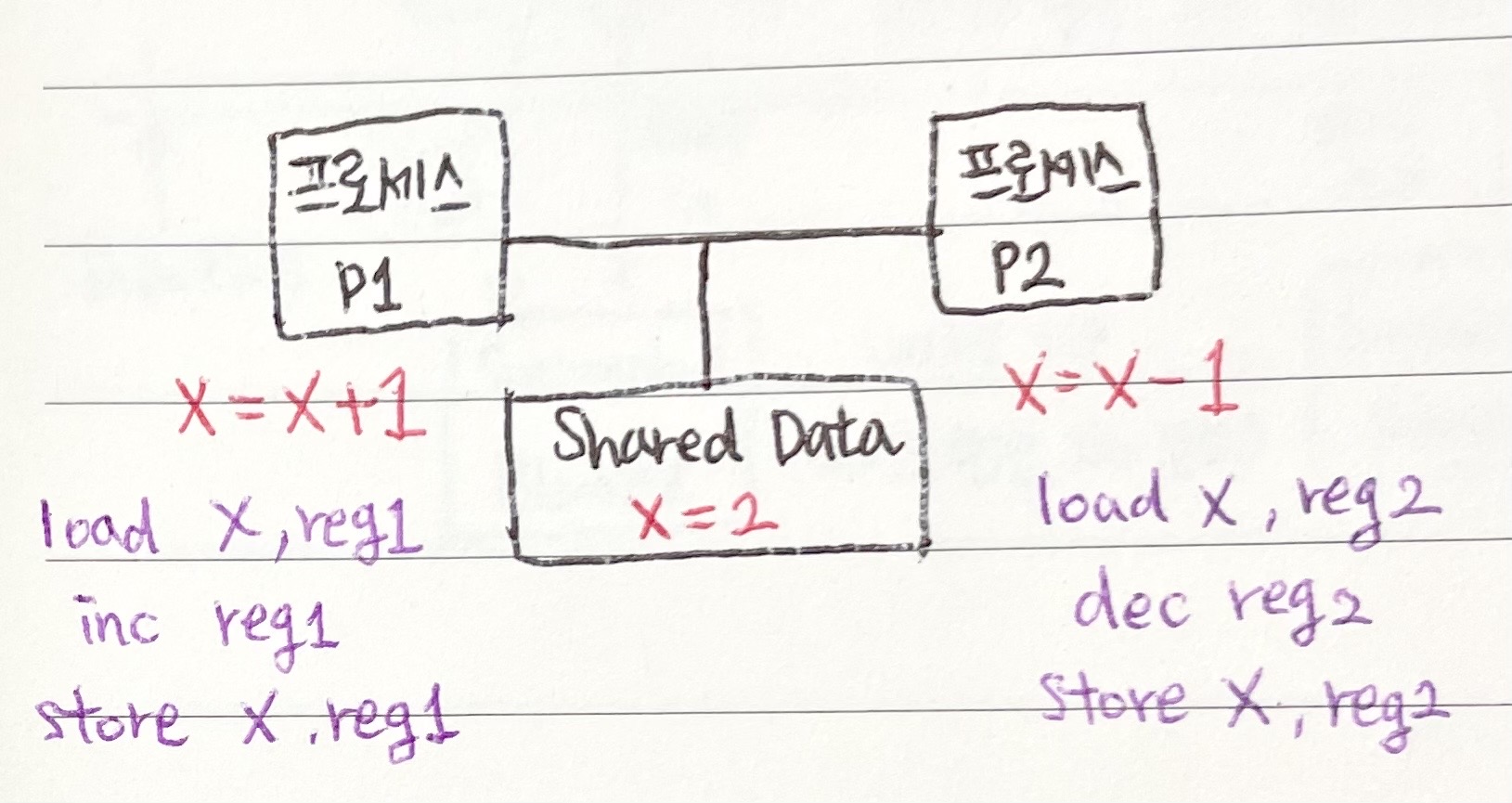
사용자 프로세스 P1 수행 중에 타이머 인터럽트가 발생 → context switch → P2가 CPU를 잡는 경우
Critical Section 문제
n개의 프로세스가 공유 데이터를 동시에 사용하기 원하는 경우
각 프로세스의 code segment에는 공유 데이터를 접근하는 코드인 critical section이 존재
따라서 하나의 프로세스가 critical section에 있을 때, 다른 프로세스는 critical section에 들어갈 수 없어야 해요.
위 그림 예시에서 critical section은 p1의 x = x + 1, p2의 x = x-1이 되겠죠.
1
2
3
4
5
6
7
8
do {
entry section // lock을 건다
/* critical section */
exit section // lock을 푼다
...
} while(1);
프로그램적 해결법의 충족 요건
모든 프로세스의 수행 속도는 0보다 크다.
프로세스들 간의 상대적인 수행 속도는 가정하지 않는다.
위 가정을 전제 하에 다음 요건을 충족 해야 합니다.
Mutual Exclusion (상호 배제)
프로세스가 critical section 부분을 수행 중이면, 다른 모든 프로세스들은 그들의 critical section에 들어가면 안된다.
Progress (진행)
아무도 critical section에 있지 않은 상태. critical section에 들어가고자 하는 프로세스가 있다면
critical section에 들어가게 해주어야 한다.Bounded Waiting (유한 대기)
프로세스가 critical section에 들어가려고 요청한 후 부터 요청이 허용될 때 까지
다른 프로세스들이 critical section에 들어가는 횟수에 한계가 있어야 한다.
알고리즘 1
아래 예시는 프로세스 P0인 경우
1
2
3
4
5
6
7
8
int turn = 0; // Pi는 turn이 i인 경우, critical section에 진입할 수 있어요.
do {
while turn != 0; // 내 턴인지 확인
/* critical section */
turn = 1 // 프로세스1에게 턴을 넘김
remainder section
}
critical section을 프로세스마다 번갈아서 들어가야 해서 상대방이 바꿔줄 때까지 내 차례를 기다려야한다는 단점이 있어요.
위 알고리즘은 Mutual Exclusion은 만족하지만 Progress가 안됩니다.
알고리즘 2
1
2
3
4
5
6
7
8
9
10
11
boolean flag[2]; // Pi가 true인 경우, critical section에 진입할 수 있어요.
do {
flag[i] = true
while (flag[j]);
/* critical section */
flag[i] = false // Pi가 out
remainder section
} while(1);
프로세스 i, j 둘 다 flag가 true가 되는 경우, 끊임 없이 양보하는 상황이 발생할 수 있습니다.
Mutual Exclusion은 만족하지만 Progress가 안됩니다.
알고리즘 3 (피터슨의 알고리즘)
알고리즘 1과 2에 있는 turn, flag (synchronization variable)를 둘다 씁니다.
“flag를 든 상태에 한해서 turn을 둬서 차례를 정하겠다”
1
2
3
4
5
6
7
8
9
10
11
12
// 프로세스 i의 입장에서 보는 코드
do {
flag[i] = true
turn = j // 다음 턴을 j로 둠
while (flag[j] && turn == j); // j가 크리티컬 섹션에 들어가고자 하는 의사가 없고 턴이 i의 차례면
/* critical section */ // i가 크리티컬 섹션에 들어간다.
flag[i] = false // 다 쓰고나면 flag를 내려서 상대 프로세스가 진입할 수 있게
remainder section
} while(1);
Mutual Exclusion, Progress, Bounded Waiting 모두 만족합니다.
다만 critical section을 못쓰는 상황이면, while문을 반복하여 계속 CPU와 메모리를 쓰면서 기다린다는 단점이 있습니다.
Busy waiting = spin lock!
Synchronization Hardware
데이터를 읽고 저장하는 과정이 Atomic하게 이루어지지 않기 때문에 Race Condition이 생김.
이걸 하드웨어적으로 Atomic하게 수행할 수 있도록 지원하는 경우 위의 문제는 간단히 해결됩니다.
Test_and_set(a) a를 읽어서 true로 세팅하는 과정을 atomic하게 진행
1
2
3
4
5
6
7
8
9
10
boolean lock = false
do {
// lock이 1이면 다른 프로세스가 critical section에 있기때문에 다음 라인으로 못가요
while (Test_and_Set(lock) );
/*critical section*/
lock = false
...
}